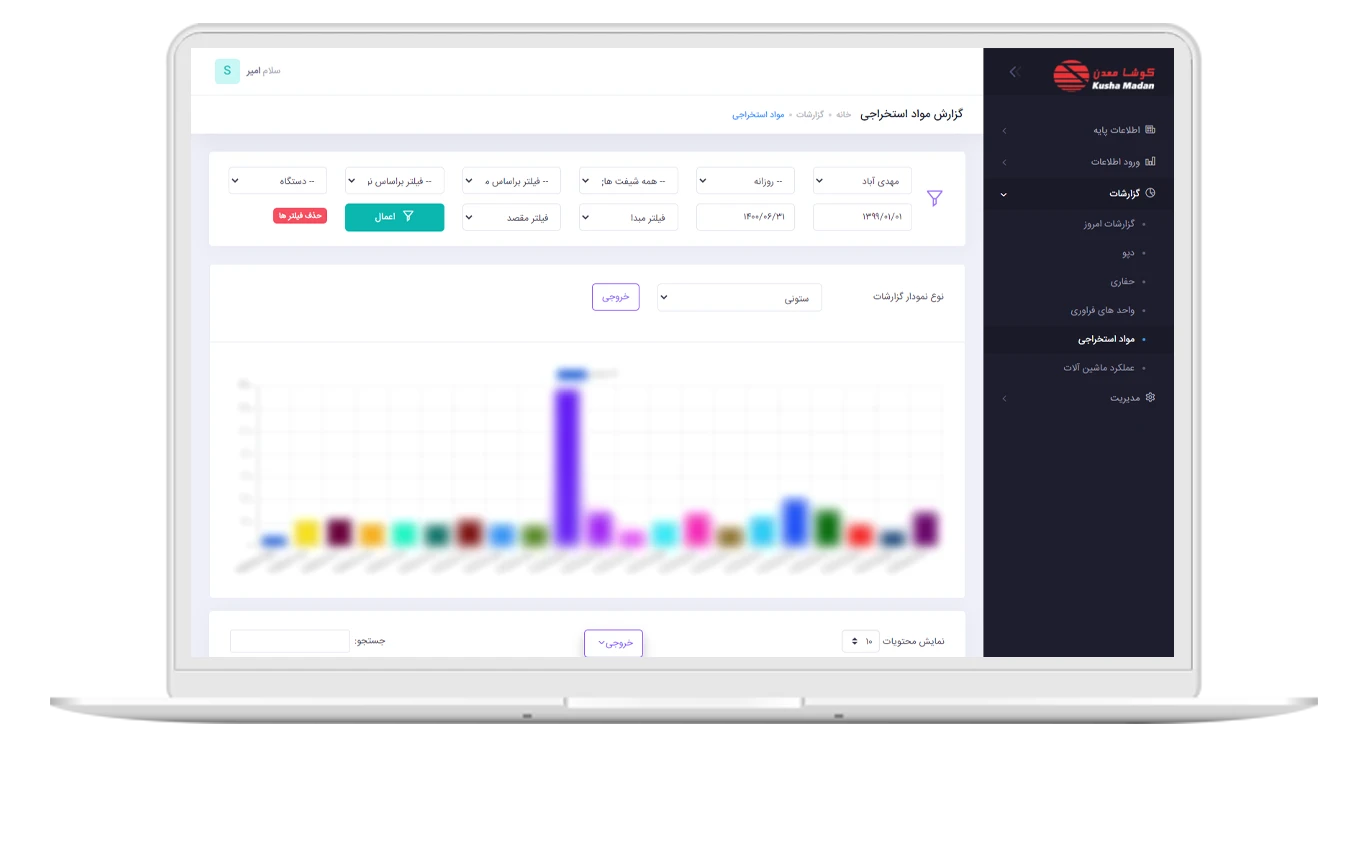
چرا ما می خواهیم ماشین آلات یاد بگیرند؟

این بیلی است بیلی می خواهد ماشین بخرد. او سعی می کند ماهانه مقداری پول برای صرفه جویی در این هزینه محاسبه کند. وی بیش از ده ها آگهی در اینترنت رفت و یاد گرفت که اتومبیل های جدید حدود 20،000 دلار هستند ، خودروهای مورد استفاده سال 19000 دلار ، 2 ساله 18000 دلار و غیره است.
بیلی شروع به دیدن الگویی می کند: بنابراین ، قیمت خودرو به سن آن بستگی دارد و هر سال 1000 دلار کاهش می یابد ، اما پایین تر از 10،000 دلار نمی رسد.
از نظر یادگیری ماشین ، بیلی رگرسیون را اختراع کرد - او یک مقدار (قیمت) را بر اساس داده های تاریخی شناخته شده پیش بینی کرد.
بله ، خوب خواهد بود که یک فرمول ساده برای هر مشکلی در جهان داشته باشید.
مشکل این است که ماشین ها دارای تاریخ های مختلف تولید ، ده ها مشخصه ، شرایط فنی و ... هستند .
مردم گنگ و تنبل هستند - برای انجام ریاضیات برای آنها به ربات ها احتیاج داریم. بنابراین ، اجازه دهید راه محاسباتی را به اینجا برسانیم. بیایید اطلاعاتی را در اختیار دستگاه قرار دهیم و از آن بخواهیم که تمام الگوهای پنهان مربوط به قیمت را پیدا کند.
جالب ترین چیز این است که دستگاه هنگام تحلیل دقیق تمام وابستگی ها در ذهن خود ، این کار را بسیار بهتر از یک شخص واقعی انجام می دهد.
این تولد یادگیری ماشین بود.
سه مؤلفه یادگیری ماشین
هوش مصنوعی ، تنها هدف یادگیری ماشین پیش بینی نتایج بر اساس داده های دریافتی است.
تنوع بیشتر در نمونه های شما ، پیدا کردن الگوهای مربوطه و پیش بینی نتیجه آسان تر است. بنابراین برای آموزش دستگاه به سه مؤلفه نیاز داریم:
داده ها می خواهند اسپم را تشخیص دهید؟ نمونه پیام های اسپم را دریافت کنید. آیا می خواهید سهام را پیش بینی کنید؟ تاریخچه قیمت را پیدا کنید. آیا می خواهید ترجیحات کاربر را دریابید؟ فعالیت های خود را در فیس بوک تجزیه کنید . هرچه داده ها متنوع تر باشد ، نتیجه بهتر می شود.

دو روش اصلی برای بدست آوردن داده ها وجود دارد - دستی و خودکار. جمع آوری داده های دستی دارای خطاهای بسیار کمتری است اما زمان بیشتری برای جمع آوری دارد - که به طور کلی آن را گرانتر می کند.
رویکرد خودکار ارزان تر است - شما همه چیز را جمع می کنید می تواند بهترین ها را پیدا کند و امیدوار باشد.
برخی ارزیابی های هوشمند مانند Google از مشتریان خود استفاده می کنند تا داده ها را به صورت رایگان برای آنها برچسب گذاری کنند. به یاد داشته باشید ReCaptcha که شما را مجبور به "انتخاب همه علائم خیابان" می کند. این دقیقاً همان کاری است که آنها انجام می دهند. نیروی کار رایگان! خوب. به جای آنها ، من شروع به نشان دادن captcha بیشتر و بیشتر می کنم.
جمع آوری داده های خوب (معمولاً به عنوان مجموعه داده) بسیار دشوار است. آنها به قدری مهم هستند که شرکتها حتی ممکن است الگوریتم های خود را فاش کنند
امکانات همچنین به عنوان پارامترها یا متغیرها شناخته می شوند. این موارد می تواند مسافت پیموده شده خودرو ، جنسیت کاربر ، قیمت سهام ، فرکانس کلمه در متن باشد. به عبارت دیگر ، اینها عواملی است که باید یک ماشین به آن نگاه کند.
وقتی داده ها در جداول ذخیره می شوند ساده هستند - ویژگی ها نام ستون ها هستند. اما اگر 100 گیگابایت عکس گربه داشته باشید چه هستند؟ ما نمی توانیم هر پیکسل را به عنوان یک ویژگی در نظر بگیریم. به همین دلیل انتخاب ویژگی های مناسب معمولاً بیشتر از سایر قسمت های ML طول می کشد. همچنین این منبع اصلی خطاها است. ذهن انسان فقط ویژگیهایی را که دوست دارد یا مهمتر است انتخاب می کند.
الگوریتم ها بارزترین قسمت. هر مشکلی می تواند متفاوت حل شود. روشی که انتخاب می کنید روی دقت ، کارایی و اندازه مدل نهایی تأثیر می گذارد. اگرچه داده ها خراب هستند ، حتی بهترین الگوریتم کمکی نمی کند. گاهی اوقات به آن "زباله در زباله ها" گفته می شود. بنابراین به درصد دقت بیش از حد توجه نکنید ، ابتدا سعی کنید اطلاعات بیشتری بدست آورید.