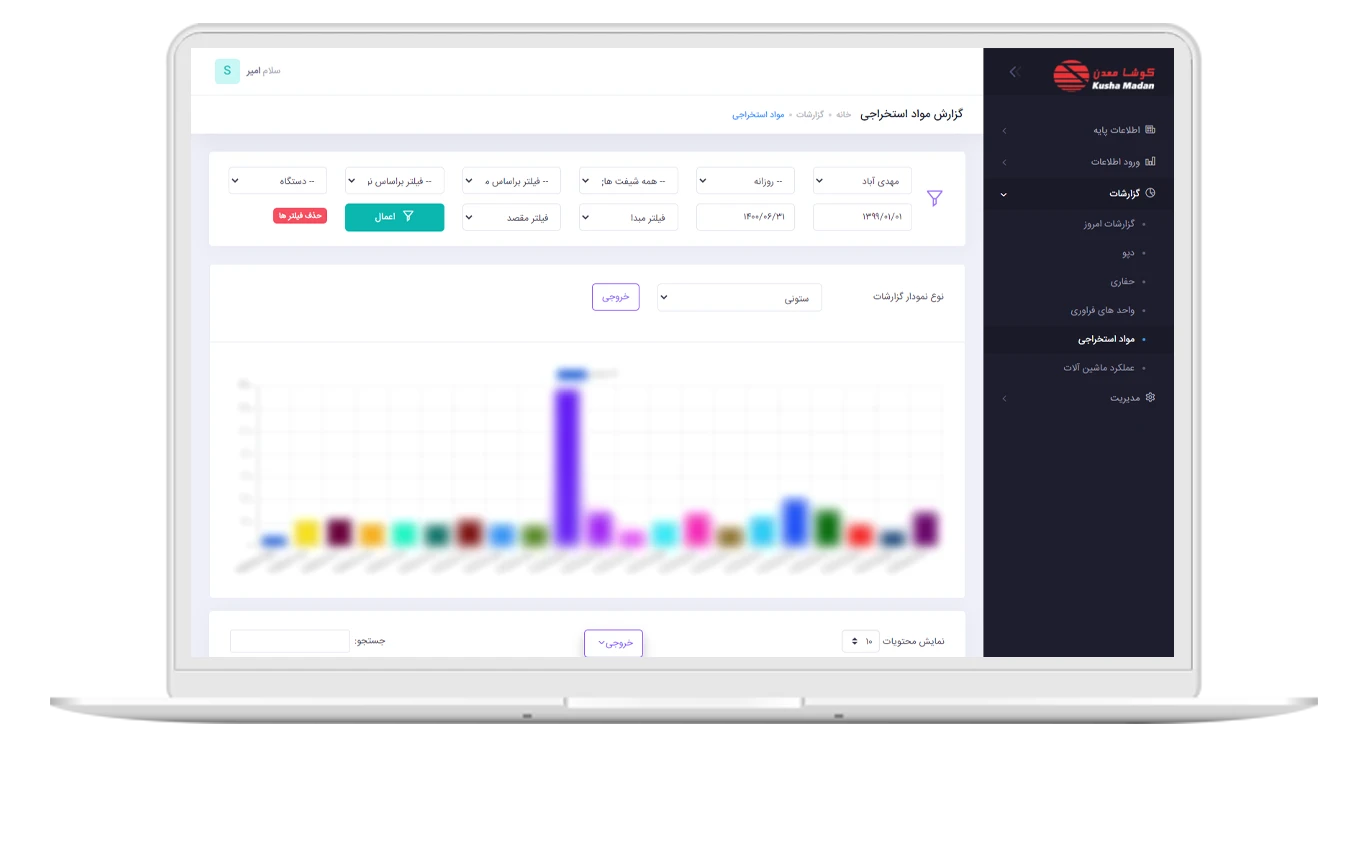
پسرفت

"خط را از طریق این نقاط بکشید. بله ، این دستگاه در حال یادگیری است"
امروز این مورد برای موارد زیر استفاده می شود:
پیش بینی قیمت سهام
تجزیه و تحلیل میزان تقاضا و حجم فروش
تشخیص پزشکی
هر نوع همبستگی
الگوریتم های محبوب رگرسیون خطی و چند جمله ای هستند.
رگرسیون اساساً طبقه بندی است که ما به جای طبقه بندی عددی را پیش بینی می کنیم. مثالها قیمت خودرو با مسافت پیموده شده آن ، ترافیک در طول روز ، حجم تقاضا با رشد شرکت و غیره است. رگرسیون زمانی مناسب است که چیزی به زمان بستگی داشته باشد.
هرکسی که با امور مالی و تجزیه و تحلیل کار می کند ، عاشق رگرسیون است. و داخل آن بسیار صاف است - دستگاه به سادگی سعی در ترسیم خطی می کند که همبستگی متوسط را نشان می دهد. اگرچه برخلاف شخصی که دارای قلم و تخته سفید است ، دستگاه با دقت ریاضی این کار را می کند و میانگین فاصله را در هر نقطه محاسبه می کند.

وقتی خط مستقیم باشد - این یک رگرسیون خطی است ، وقتی منحنی است - چند جمله ای. این دو نوع اصلی رگرسیون هستند. موارد دیگر عجیب و غریب تر هستند. رگرسیون لجستیک یک گوسفند سیاه در گله است. اجازه ندهید که شما را فریب دهد ، زیرا این یک روش طبقه بندی است ، نه رگرسیون.
اشکالی ندارد که با رگرسیون و طبقه بندی اشتباه کنیم. بسیاری از طبقه بندی ها پس از تنظیماتی به رگرسیون تبدیل می شوند. ما نه تنها می توانیم کلاس شی را تعریف کنیم بلکه به یاد داشته باشیم که چقدر نزدیک است. در اینجا یک رگرسیون آمده است.
یادگیری بدون نظارت
بدون نظارت کمی بعد ، در دهه 90 اختراع شد. کمتر از آن استفاده می شود ، اما بعضی اوقات ما چاره ای نداریم.
داده ها برچسب زده لوکس هستند. اما اگر بخواهم بیاییم طبقه بندی اتوبوس را ایجاد کنم ، چه می شود؟ آیا باید به صورت دستی از میلیون اتوبوس در خیابان عکس بگیرم و هر کدام را برچسب گذاری کنیم؟ به هیچ وجه ، این یک عمر طول خواهد کشید.
می توانید سعی کنید از یادگیری بدون نظارت استفاده کنید. معمولاً برای تجزیه و تحلیل داده های اکتشافی مفید است اما به عنوان الگوریتم اصلی نیست. مغز آموزش دیده ی انسان با درجه آکسفورد دستگاه را با یک تن زباله تغذیه می کند و آن را تماشا می کند. آیا خوشه ای وجود دارد؟ شماره روابط قابل رویت؟ نه ، خوب ، پس از آن ادامه دهید شما می خواهید در علم داده کار کنید ، درست است؟
دسته کردن

"اشیاء را بر اساس ویژگی های ناشناخته تقسیم می کند. دستگاه بهترین راه را انتخاب می کند"
امروزه استفاده می شود:
- برای تقسیم بازار (انواع مشتری ، وفاداری)
- برای ادغام نقاط نزدیک در نقشه
- برای فشرده سازی تصویر
- برای تجزیه و تحلیل و برچسب گذاری داده های جدید
- برای تشخیص رفتار غیر طبیعی
الگوریتم های محبوب: K-معنی_clustering ، میانگین-شیفت ، DBSCAN
خوشه بندی طبقه بندی بدون کلاس ها از پیش تعریف شده است . الگوریتم خوشه بندی در تلاش برای یافتن اشیاء مشابه (توسط برخی ویژگی ها) و ادغام آنها در یک خوشه. کسانی که ویژگی های مشابه زیادی دارند ، در یک کلاس قرار می گیرند. با برخی از الگوریتم ها ، حتی می توانید تعداد دقیق خوشه های مورد نظر خود را مشخص کنند.
یک نمونه عالی از نشانگرهای خوشه بندی در نقشه های وب. هنگامی که به دنبال تمام رستوران ها در اطراف هستید ، موتور خوشه بندی آنها را به سمت تعدادی حباب گروه بندی می کند. در غیر این صورت ، مرورگر شما یخ می زند ، تلاش می کند هر سه میلیون رستوران در مرکز شهر ترسیم کند.
Apple Photos و Google Photos از خوشه بندی پیچیده تر استفاده می کنند. آنها برای ایجاد آلبوم از دوستان شما به دنبال چهره در عکس ها هستند. این برنامه نمی داند که چند دوست دارید و چگونه به نظر می رسند ، اما سعی در پیدا کردن ویژگی های متداول صورت دارد. خوشه بندی معمولی.
مسئله محبوب دیگر فشرده سازی تصویر است. هنگام ذخیره تصویر در PNG ، می توانید بگویید پالت ، 32 رنگ را تنظیم کنید. این بدان معنی است که خوشه بندی پیکسل های "قرمز" را پیدا می کند ، "قرمز متوسط" را محاسبه می کند و آن را برای همه پیکسل های قرمز تنظیم می کند. رنگهای کمتری - سایز پرونده پایین - سود!
با این وجود ، ممکن است در مورد رنگ هایی مانند Cyan◼︎ مشکلاتی داشته باشد. سبز است یا آبی؟ در اینجا الگوریتم K-Means آمده است.
به طور تصادفی 32 نقطه رنگ را در پالت تنظیم می کند. اکنون ، این افراد سانتریفیوژ هستند. نقاط باقیمانده به عنوان نزدیکترین سانتروئید اختصاص داده می شوند. بنابراین ، ما به این نوع از کهکشان ها در حدود 32 رنگ می پردازیم. سپس سانتروئید را به مرکز کهکشان آن منتقل می کنیم و این کار را تکرار می کنیم تا اینکه سانتریفیدها از حرکت خود متوقف شوند.
تمام شد خوشه ها تعریف شده ، پایدار هستند و دقیقاً 32 مورد از آنها وجود دارد. در اینجا توضیحی در دنیای واقعی ارائه شده است:
 جستجوی سانتریفوژها راحت است. اگرچه ، در زندگی واقعی خوشه ها همیشه دور نیستند. بیایید تصور کنیم شما یک زمین شناس هستید. و شما باید برخی از مواد معدنی مشابه را در نقشه پیدا کنید. در این حالت ، خوشه ها را می توان به طرز عجیبی شکل داد و حتی لانه کرد. همچنین ، شما حتی نمی دانید چه تعداد از آنها انتظار دارید.
جستجوی سانتریفوژها راحت است. اگرچه ، در زندگی واقعی خوشه ها همیشه دور نیستند. بیایید تصور کنیم شما یک زمین شناس هستید. و شما باید برخی از مواد معدنی مشابه را در نقشه پیدا کنید. در این حالت ، خوشه ها را می توان به طرز عجیبی شکل داد و حتی لانه کرد. همچنین ، شما حتی نمی دانید چه تعداد از آنها انتظار دارید.
K-means در اینجا مناسب نیست ، اما DBSCAN می تواند کمک کننده باشد. بیایید بگوییم نقاط ما مردم در میدان شهر هستند. هر سه نفر را که در کنار یکدیگر ایستاده اند پیدا کنید و از آنها بخواهید که دست خود را نگه دارند. سپس به آنها بگویید که دست گرفتن آن دسته از همسایگان را که می توانند برسند ، شروع کنند. و غیره تا زمانی که دیگر کسی نتواند دست کسی را بگیرد. این اولین خوشه ماست این روند را تکرار کنید تا همه خوشه بندی شوند.
همه اینها جالب به نظر می رسد:
درست مانند طبقه بندی ، می توان از خوشه بندی برای تشخیص ناهنجاری ها استفاده کرد. کاربر بعد از ثبت نام رفتار غیرطبیعی می کند؟ بگذارید دستگاه او را به طور موقت ممنوع کند و برای بررسی آن ، بلیطی را برای پشتیبانی ایجاد کند. شاید یک ربات باشد. حتی لازم نیست بدانیم که "رفتار عادی" چیست ، ما فقط تمام عملکردهای کاربر را بر روی مدل خود بارگذاری می کنیم و اجازه می دهیم دستگاه تصمیم بگیرد که آیا این کاربر "معمولی" است یا نه.
این روش در مقایسه با طبقه بندی خوب کار نمی کند ، اما هرگز امتحان کردن ضرری ندارد.