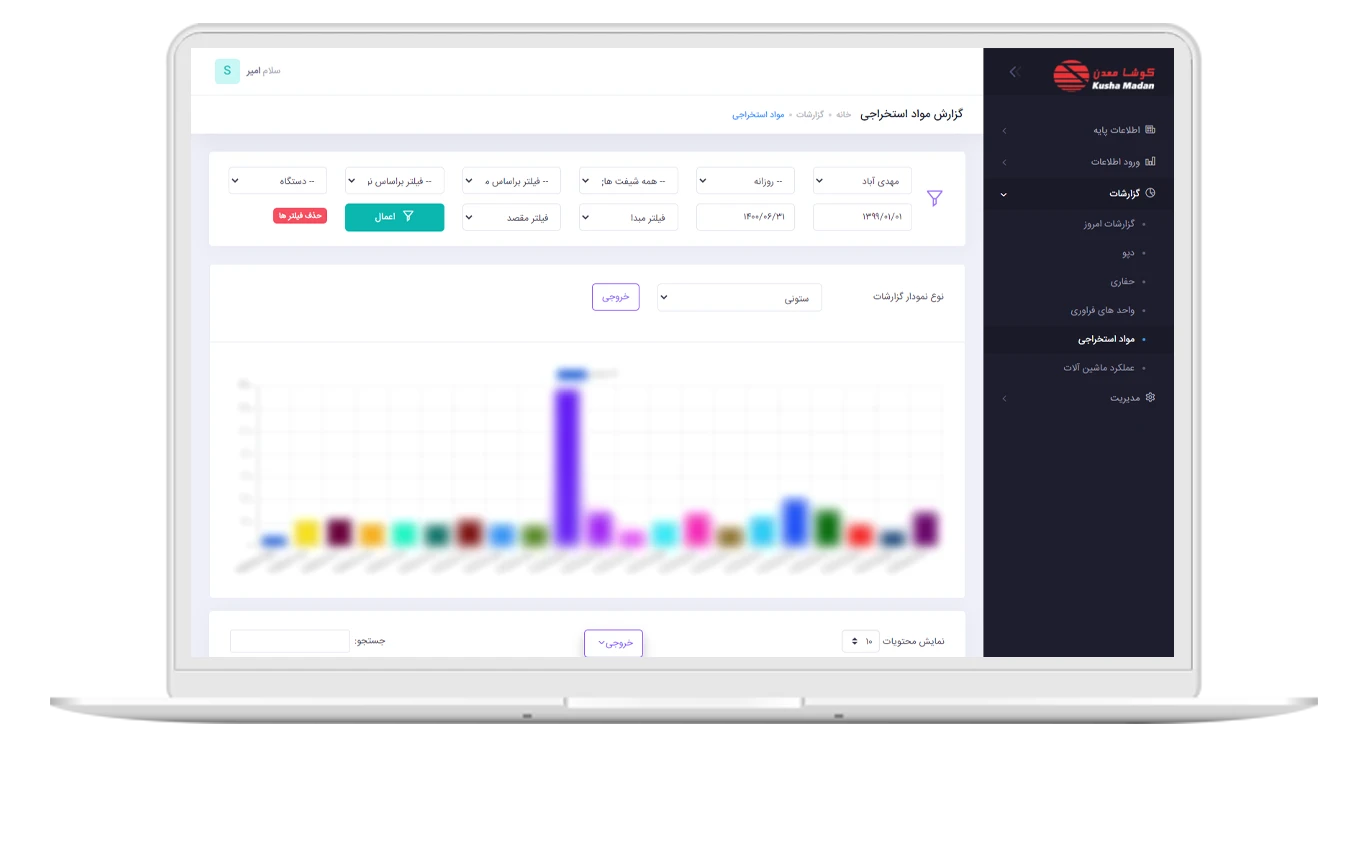
یادگیری قانون انجمن
 "به دنبال الگوهای موجود در جریان سفارشات" امروزه استفاده می شود:
"به دنبال الگوهای موجود در جریان سفارشات" امروزه استفاده می شود:
- برای پیش بینی فروش و تخفیف
- برای تجزیه و تحلیل کالاهای خریداری شده
- برای قرار دادن محصولات در قفسه ها
- برای تحلیل الگوهای گشت و گذار در وب
الگوریتم های محبوب: Apriori، Euclat، FP-growth
این الگوریتم ها شامل تمام روشها برای تجزیه و تحلیل سبد خرید ، خودکار استراتژی بازاریابی و سایر وظایف مرتبط با رویداد هستند. وقتی دنباله ای از چیزی دارید و می خواهید الگویی در آن بیابید - این ها را امتحان کنید.
هیچ تصوری نیست که چرا به نظر می رسد یادگیری قانون کمترین بحث در مورد دسته یادگیری ماشین است. روش های کلاسیک مبتنی بر نگاهی کلی به تمام کالاهای خریداری شده با استفاده از درختان یا مجموعه ها است. الگوریتم ها فقط می توانند به جستجوی الگوها بپردازند ، اما نمی توانند نمونه های جدید را تعمیم داده یا بازتولید کنند.
در دنیای واقعی ، هر خرده فروش بزرگ راه حل اختصاصی خود را می سازد ، بنابراین انقلاب های ظریف در اینجا برای شما وجود دارد.

- یادگیری تقویتی

"یک روبات را به پیچ و خم پرتاب کنید و بگذارید یک خروجی پیدا کند"
امروزه استفاده می شود برای:
اتومبیل های خودران
خلاء ربات
بازی ها
تجارت خودکار
مدیریت منابع سازمانی
الگوریتم های محبوب: Q-Learning، SARSA، DQN، A3C، الگوریتم ژنتیک
سرانجام ، به چیزی شبیه هوش مصنوعی واقعی می رسیم. در بسیاری از مقالات ، یادگیری تقویتی در جایی بین یادگیری نظارت و نظارت نشده قرار می گیرد. آنها هیچ مشترکی ندارند! آیا این به خاطر نام است؟
یادگیری تقویت در مواردی استفاده می شود که مشکل شما به هیچ وجه مربوط به داده ها نیست ، اما شما محیطی برای زندگی در آن دارید. مانند دنیای بازی های ویدئویی یا شهری برای اتومبیل رانندگی.
آگاهی از کلیه قوانین جاده ای در جهان به autopilot نمی آموزد که چگونه در جاده ها رانندگی کند. صرف نظر از چقدر داده های جمع آوری شده ، ما هنوز هم نمی توانیم همه شرایط ممکن را پیش بینی کنیم. به همین دلیل هدف آن به حداقل رساندن خطا است ، نه پیش بینی همه حرکات.
ایده اصلی برای یادگیری تقویت زنده ماندن در یک محیط است. ربات کوچک فقیر را به زندگی واقعی پرتاب کنید ، آن را برای اشتباهات مجازات کنید و آن را برای اعمال صحیح پاداش دهید. به همان روشی که ما به بچه هایمان آموزش می دهیم ، درست است؟
روش مؤثرتر در اینجا - برای ساختن یک شهر مجازی و اجازه دادن به اتومبیل رانندگی که در ابتدا همه ترفندهای خود را در آنجا بیاموزد. این دقیقاً همین است که ما اکنون خلبانان خودکار را آموزش می دهیم. بر اساس یک نقشه واقعی ، یک شهر مجازی ایجاد کنید ، با عابران پیاده زندگی کنید و بگذارید ماشین یاد بگیرد تا حد ممکن تعداد کمی از مردم را بکشد. هنگامی که ربات از نظر منطقی به این GTA مصنوعی اطمینان دارد ، برای تست در خیابان های واقعی آزاد می شود. سرگرم کننده است.
ممکن است دو رویکرد متفاوت وجود داشته باشد - مبتنی بر مدل و بدون مدل.
مبتنی بر مدل بدان معنی است که ماشین باید از یک نقشه یا قسمتهای آن یادآوری کند. این یک رویکرد بسیار قدیمی است از آنجا که غیرقانونی بودن اتومبیل سواری نمی تواند تمام سیاره را به خاطر بسپارد.
در یادگیری بدون مدل ، ماشین از هر حرکتی به یاد نمی آورد ، اما سعی می کند موقعیت ها را تعمیم دهد و ضمن کسب یک پاداش حداکثر ، عقلانی رفتار کند.
 به یاد داشته باشید اخبار مربوط به ضرب و شتم AI در بازی Go ، یک بازیکن برتر است. با وجود کمی قبل از این ثابت شد که تعداد ترکیبات در این بازی از تعداد اتمهای جهان بیشتر است.
به یاد داشته باشید اخبار مربوط به ضرب و شتم AI در بازی Go ، یک بازیکن برتر است. با وجود کمی قبل از این ثابت شد که تعداد ترکیبات در این بازی از تعداد اتمهای جهان بیشتر است.
این بدان معنی است که دستگاه نمی تواند تمام ترکیب ها را به خاطر آورد و بدین ترتیب برنده Go (همانطور که شطرنج کرد) بود. در هر نوبت ، به سادگی بهترین حرکت را برای هر موقعیتی انتخاب می کرد ، و به خوبی آن را انجام می داد تا یک ذهن انسان را ترسیم کند.
این رویکرد یک مفهوم اصلی در پشت یادگیری Q و مشتقات آن است (SARSA & DQN). Q "" در اسم مخفف "Quality" است به عنوان روباتی یاد می گیرد که "عملی ترین" عمل را در هر موقعیت انجام دهد و تمام موقعیت ها به عنوان یک فرآیند ساده مارکویز یاد می شوند.
 چنین دستگاهی می تواند میلیارد ها موقعیت را در یک محیط مجازی آزمایش کند ، و به یاد می آورد که راه حل ها منجر به پاداش بیشتر می شود. اما چگونه می تواند شرایط قبلی را از یک وضعیت کاملاً جدید متمایز کند؟ اگر یک اتومبیل خودران در یک گذرگاه باشد و چراغ راهنما سبز شود - آیا این بدان معنی است که اکنون می تواند برود؟ چه اتفاقی می افتد اگر یک آمبولانس با خیابانی در نزدیکی خیابان تردد کند؟
چنین دستگاهی می تواند میلیارد ها موقعیت را در یک محیط مجازی آزمایش کند ، و به یاد می آورد که راه حل ها منجر به پاداش بیشتر می شود. اما چگونه می تواند شرایط قبلی را از یک وضعیت کاملاً جدید متمایز کند؟ اگر یک اتومبیل خودران در یک گذرگاه باشد و چراغ راهنما سبز شود - آیا این بدان معنی است که اکنون می تواند برود؟ چه اتفاقی می افتد اگر یک آمبولانس با خیابانی در نزدیکی خیابان تردد کند؟
پاسخ امروز "هیچ کس نمی داند" چیست. هیچ جواب آسانی وجود ندارد محققان به طور مداوم در جستجوی آن هستند اما در عین حال تنها راه حل پیدا می کنند. برخی از آنها همه وضعیتها را به صورت دستی کدگذاری می کنند که به آنها اجازه می دهد موارد استثنایی را حل کنند ، مانند مشکل واگن برقی. برخی دیگر عمیق خواهند شد و به شبکه های عصبی اجازه می دهند کار را برای کشف کردن انجام دهند. این ما را به سمت تکامل یادگیری Q به نام Deep Q-Network (DQN) سوق می دهد. اما آنها یک گلوله نقره ای نیز نیستند.
تقویت آموزش یادگیری برای یک فرد معمولی مانند یک هوش مصنوعی واقعی به نظر می رسد. از آنجا که باعث می شود فکر کنید ، این دستگاه در شرایط واقعی زندگی تصمیم گیری می کند! این موضوع در حال حاضر بسیار شفاف است ، با سرعت باورنکردنی پیش می رود و با یک شبکه عصبی تلاقی می کند تا کف شما را با دقت بیشتری تمیز کند. دنیای شگفت انگیز فن آوری ها!
بشریت هنوز نتوانسته است وظیفه ای پیدا کند که در آن روشها مؤثرتر از سایر روشها باشند. اما آنها برای آزمایشات دانشجویی عالی هستند و به افراد اجازه می دهند که سرپرستان دانشگاه خود را بدون "زحمت زیاد" از "هوش مصنوعی" هیجان زده کنند.